
Our operating systems are incorrectly factored
Thu 5 May 2016 15:48 EDT

Unix famously represents all content as byte sequences. This was a great step forward, offering a way of representing arbitrary information without forcing an interpretation on it.
However, it is not enough. Unix is an incomplete design. Supporting only byte sequences, and nothing else, has caused wasted effort, code duplication, and bugs.
Text is an obvious example of the problem
Consider just one data type: text. It has a zillion character sets and encoding schemes. Each application must decide, on its own, which encoding of which character set is being used for a given file.
When applications get this wrong, both obvious bugs like Mojibake and subtler flaws like the IDN homograph attack result.
Massive duplication of code and effort
Lack of system support for text yields massive code duplication. Rather than having a system-wide, comprehensive model of text representation, encoding, display, input, collation, and comparison, each programming language and application must fend for itself.
Because it is difficult and time consuming to properly handle text, developers tend to skimp on text support. Where a weakness is identified, it must be repaired in each application individually rather than at the system level. This is itself difficult and time consuming.
Inconsistent treatment
Finally, dealing only with byte sequences precludes consistent user interface design.
Consider a recent enhancement to Thunderbird, landing in version 45.0. Previously, when exporting an address book as CSV, only the “system character set” was supported. Now, the user must specify which character set and encoding is to be used:
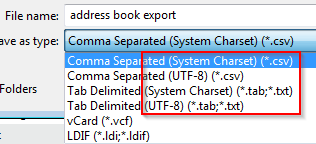
The user cannot simply work with a file containing text; they must make a decision about which encoding to use. Woe betide them if they choose incorrectly.
A consistent approach would separate the question of text encodings entirely from application-specific UIs. System UI for transcoding would exist in one place, common to all applications.
User frustration
A tiny fraction of the frustration this kind of thing causes is recorded in Thunderbird’s bug 117236.
Notice that it took fourteen years to be fixed.
Ubiquitous problem
This Thunderbird change is just one example. Each and every application suffers the same problems, and must have its text support repaired, upgraded, and enhanced independently.
It’s not only a Unix problem. Windows and OS X are just as bad. They, too, offer no higher-level model than byte sequences to their applications. Even Android is a missed opportunity.
Learn from the past
Systems like Smalltalk, for all their flaws, offer a higher-level model to programmers and users alike. In many cases, the user never need learn about text encoding variations.
Instead, the system can separate text from its encoding.
Where encoding is relevant to the user, there can be a single place to work with it. Contrast this with the many places encoding leaks into application UIs today, just one of which is shown in the Thunderbird example above.
It’s not just text
Text is just one example. Pictures are another. You can probably think of more.
Our operating systems do not support sharing of high-level abstractions of data between documents or applications.
An operating system with a mechanism for doing so would take a great burden off both programmers and users.
Let’s start thinking about what a better modern operating system would look like.