Erik Meijer recently explained the duality of Enumeration and
Observation.
Subscribing to a feed of items is
dual to
retrieving an enumerator and going through the items.
Reading his article, I was surprised to realise that there’s a
corresponding symmetry between credit-based flow control and
message acknowledgement!
Generalising the idea of polling (enumeration) yields flow control,
and generalising subscription (observation) yields acknowledgement.
Flow control and Acknowledgement
When designing network protocols such as TCP or AMQP, two problems
arise that are both crucial to the robustness and performance of the
system being designed:
- How do we avoid flooding a receiver with messages? and
- How do we know when a receiver successfully received a message?
The solutions to these problems are flow control and
acknowledgements, respectively. The rest of this article will show
how these solutions arise from plain old enumeration and
observation. I’ll briefly comment on their manifestations in TCP and
AMQP toward the end.
Enumeration and Observation
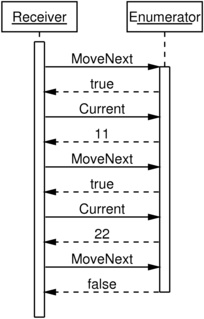
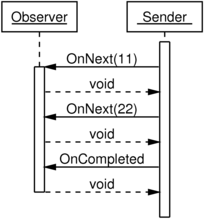
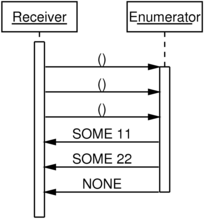
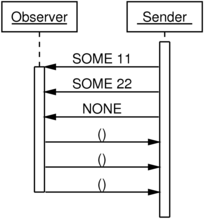
These message sequence diagrams illustrate the use of .NET’s
IEnumerator<T>
and
IObserver<T>
as described in Erik’s article. In each diagram, the application is
working with some collection containing two values, 11 and 22.
It’s hard to see the symmetry by looking at the diagrams above. The
design of .NET’s IEnumerator<T> API is obscuring it by separating
MoveNext from Current.
To really see the symmetry properly, we’ll move to a language where we
can use algebra to simplify the
problem: SML.
SML types for enumeration and observation
The SML type corresponding
to IEnumerator<T> might be written as the following (ignoring
exceptions, since they aren’t really relevant to the problem at hand):
type 'a enumerator = (unit -> bool) * (unit -> 'a)
This is a pair of methods, (MoveNext, Current), corresponding
directly to the methods in .NET’s IEnumerator<T> interface. Since
it doesn’t make sense to be able to call Current if MoveNext has
returned false, by applying a little domain-knowledge and a little
algebra we see that this
definition is equivalent to the simpler:
type 'a enumerator = unit -> 'a option
We have combined the two methods together, eliminating the possibility
of making a mistake. A NONE result from the single combined method
indicates that there are no more values available, and a SOME v
result carries the next available value v if there is one.
Translating Erik’s almost-mechanically-derived IObserver<T>
interface to SML, again ignoring exceptions, and following the 'a
option rewrite we used on enumerator, we arrive at:
type 'a observer = 'a option -> unit
The duality is crystal clear at this point. An enumerator has type
unit -> 'a option, where an observer has type 'a option -> unit.
Enumerators act as senders of information, and Observers act as
receivers.
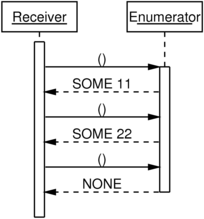
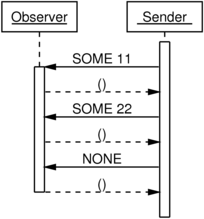
Here’s a message sequence diagram, equivalent to the one above, but
using the SML types instead of the .NET interfaces:
Now the symmetry really stands out.
On the left, we can see that when enumerating, an information-free ()
message indicates that the receiver is ready for the next piece of
information from the sender. This is
(credit-based) flow control!
On the right, we can see that when observing, an information-free ()
message indicates that the receiver has finished processing the
most-recently-sent piece of information from the sender. This is acknowledgement!
Enumerators work by the receiver issuing a unit of flow-control
credit, and the sender then sending a single value. Observers work by
the sender sending a single value, and the receiver then issuing a
single acknowledgement message.
Pipelining credit and acknowledgement messages
Let’s take this a step closer to a real network protocol by
introducing pipelining of messages. It’s important to be able to
reduce latency by decoupling the issuing of a request from the
processing of that request. Here we drop the notational distinction
between requests and responses, drawing just one kind of arrow for
both kinds of message.
All we’ve done here is moved all the “requests” up to the top of each
sequence, and all the “responses” to the bottom.
Remember that on the left, () indicates an issue of credit, so that
the sender is permitted to send an additional piece of information to
the receiver, while on the right, () indicates acceptance of a
preceding piece of information by the receiver.
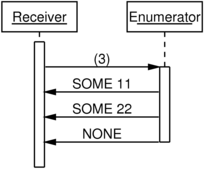
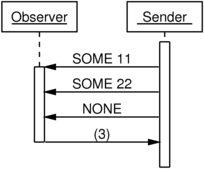
Batching pipelined credit and acknowledgement messages
We can save some bandwidth by applying some of the algebraic tricks we
used earlier, looking for a way of compressing those sequences of ()
messages into informationally equivalent batch credit-issues and
acknowledgement messages.
Recall that our enumerator function takes a single () and returns an
'a option, which means either the next available datum or the end of
stream:
type 'a enumerator = unit -> 'a option
Switching from SML to abstract type algebra for a moment, let’s model
pipelined requests and responses as lists. The algebraic types
involved (don’t forget this introduction to type
algebra) are
RequestPipeline = 1 + (1 * RequestPipeline)
ReplyPipeline = 1 + (Value * ReplyPipeline)
These are equivalent to
RequestPipeline = 1 + 1*1 + 1*1*1 + 1*1*1*1 + ...
ReplyPipeline = 1 + Value + Value*Value + Value*Value*Value + ...
Now, there’s nothing sensible we can do to compress the reply pipeline
in the absence of special knowledge about the sequence of values being
transferred, but the request pipeline looks very repetitive. It is, in
fact, a unary representation of natural numbers. We can use a binary
representation instead to save enormous amounts of bandwidth.
Analogous reasoning lets us compress the stream of acknowledgements
leaving an observer, so let’s use natural numbers to model our batched
credit-issue messages and acknowledgement messages:
Notice how in each case we’ve replaced three separate information-free
messages with a single message carrying a natural number,
3. Pipelining and batching credit and acknowledgement messages
improves both latency of delivery and usage of available bandwidth.
Analyzing TCP and AMQP
TCP has an elegant flow- and retransmission-control mechanism, the
sliding
window. Each
byte in a TCP stream is separately numbered so that it can be referred
to unambiguously. Each TCP segment contains an ACK field that tells
a sender which bytes a receiver has seen so far: in other words, the
ACK field acknowledges received data. Each segment also contains a
Window Size field that tells the sender how much more data it is
currently permitted to send: in other words, the amount of credit the
receiver is willing to issue.
Looking at things through the lens of the enumerator/observer duality,
it’s clear that TCP makes use of both interfaces simultaneously,
since it is both issuing flow credit and acknowledging data
receipt. There is some generalisation of both interfaces waiting to be
exposed! I hope to write more on this in a future article.
Another interesting aspect of TCP is the way that it numbers its FIN
segments as part of the transmitted data stream, ensuring reliable
notification of stream termination. This
corresponds to the acknowledgement of the final NONE in the sequence
diagrams above. You might think that the acknowledgement of the end of
a stream was optional, but if you omit it, the reliable-delivery
characteristics of the protocol change quite substantially: you’re
forced to either introduce an out-of-band reliable shutdown
subprotocol, or to fairly drastically change the way timeouts are used
to decide how long to retain the necessary state.
AMQP also includes something similar to credit-based flow control and
message acknowledgements. Flow credit can be arranged by using a
Basic.Qos
command before transmission begins, and acknowledgement of received
messages is done using
Basic.Ack
commands. However, the protocol combines replenishment of credit with
acknowledgement of data: Basic.Ack has a dual role (pardon the
pun). Ideally replenishment of flow credit would be done separately
from acknowledgement of data, with a command for each task, mirroring
the way TCP uses a separate header field for each function.
Besides AMQP’s core subscription system, centred around
Basic.Consume,
there is a less-commonly-used polling based method of transferring
messages,
Basic.Get. Basic.Get
is very close to being an instance of the simple SML 'a enumerator
function type introduced above, and doesn’t include any way of
pipelining or batching requests or responses.
Conclusions and future work
The duality between IEnumerator<T> and IObserver<T> extends into a
network protocol setting. By looking at it in a network protocol
context, we can see the natural emergence of credit-based flow control
on the one hand, and acknowledgement on the other. With this model of
a data transfer protocol in mind, we can examine existing protocols
such as TCP and AMQP to see how they map to the operations we have
identified.
There are one or two remaining loose ends I’m interested in following
up. Firstly, what is the generalisation of both interfaces, so evident
in both TCP and AMQP, like? Whatever it is, it could turn out to be a
good candidate for a generalised model of a flow-controlled reliable
information stream. Secondly, both IEnumerator<T> and IObserver<T>
are inherently stateful approaches to data streaming. What do we see
if we switch to pure-functional models of enumeration and observation?
What are the analogous network protocol models like? I suspect that
the answers here will lead in the direction of more
RESTful
models of message transmission such as
RestMS and
ReverseHTTP.