Back in March, I (crudely)
measured
the performance of js-nacl
and js-scrypt running in
the Browser.
Since then, emscripten has improved its code generation
significantly, so I’ve rerun my tests. I’ve also thrown in node.js for
comparison.
The takeaway is: asm.js makes a big
difference to NaCl and scrypt performance - on Firefox, that
is. Firefox is between 2× and 8× faster. Other browsers
have benefited from the improvements, but not as much.
The setup:
- Firefox/23.0
- Chrome/28.0.1500.95
- Safari/534.59.8
- node/v0.10.15
- Macbook Air late 2010 (3,1), 1.6 GHz Core 2 Duo, 4 GB RAM, OS X 10.6.8
I’m running emscripten at git revision b1eaf55e
(sources),
of 8 August 2013.
(The benchmarks I ran in March were run with rev 4e09482e
(sources)
of 16 Jan 2013.)
What has changed since the last measurements?
Emscripten’s support for asm.js code generation is much better, and I
am also now able to turn on -O2 optimization without things
breaking.
On the minus side, the previous builds included a severe memory leak
(!) because by default Emscripten includes a stub malloc() and
free() implementation that never releases any allocated memory. The
current builds include dlmalloc(), and so no longer leak memory, but
run ever so slightly slower by comparison to using the stub allocator.
Safari seems to have severe problems with the current builds. I’m
unsure where the bug lies (probably emscripten?), but many calls to
crypto_box/crypto_box_open and scrypt() yield incorrect
results. There are missing entries in the charts below because of
this. (No sense in measuring something that isn’t correct.)
Since the previous round, Firefox has gained support for
window.crypto.getRandomValues. Hooray!
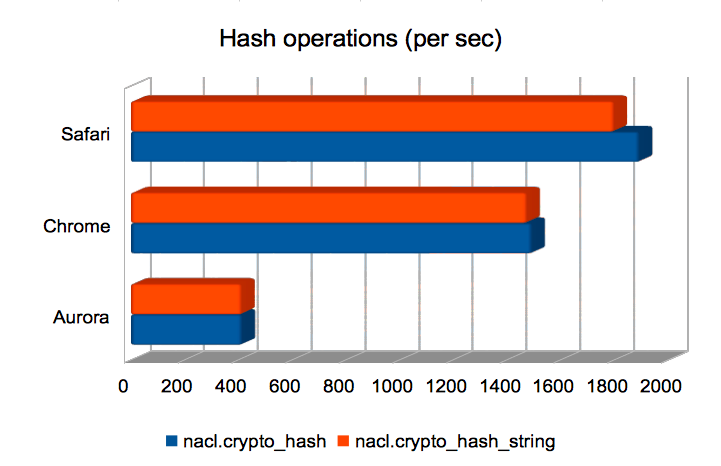
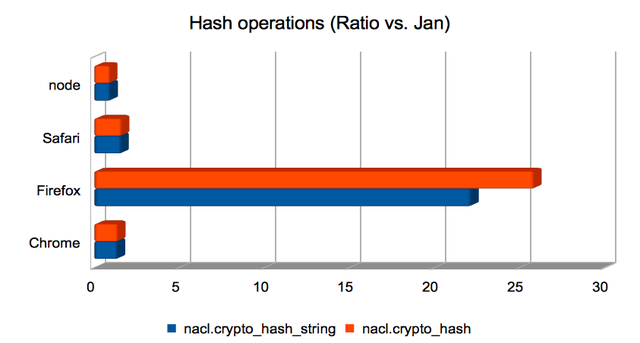
Hashing (short) strings/bytes with SHA-512
Firefox handily dominates here, making the others look roughly equivalent.
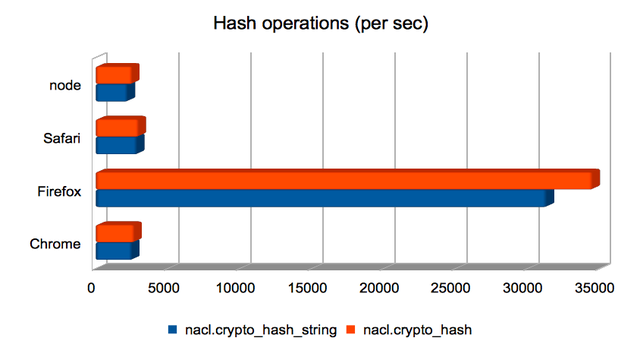
(Approximate speedups since January: Chrome = 1.2×; Firefox = 8.3×; Safari = 1.4×; node = 0.95×. Chart.)
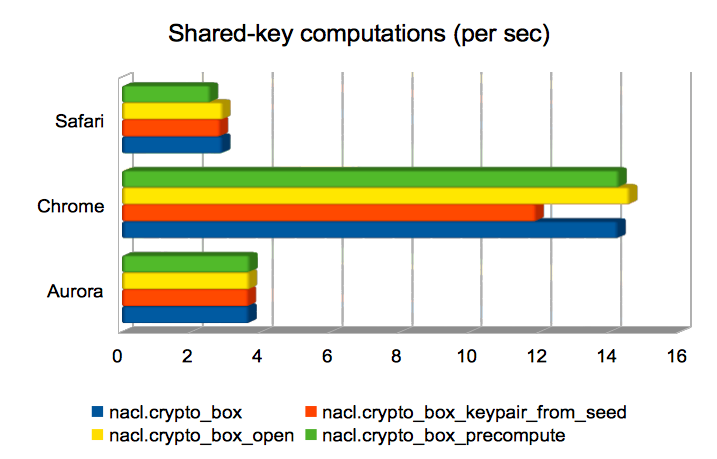
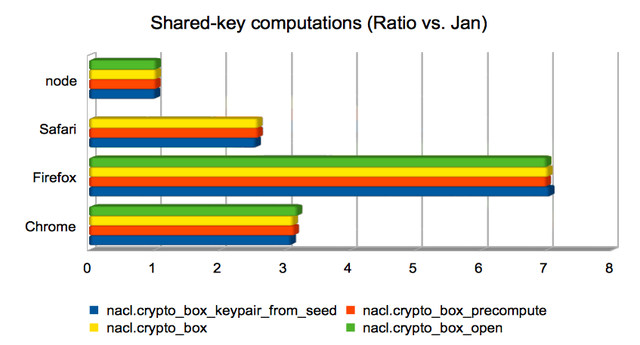
Computing a shared key from public/private keys
These are operations whose runtime is dominated by the computation of
a Curve25519 operation. In three of the
four cases, the operation is used to compute a Diffie-Hellman shared
key from a public key and a secret key; in the remaining case
(crypto_box_keypair_from_seed) it is used to compute a public key
from a secret key. Firefox again dominates, but Chrome is not far
behind.
This is one of the areas where Safari yields incorrect results,
leading to a missing data point. I’m not yet sure what the cause is.
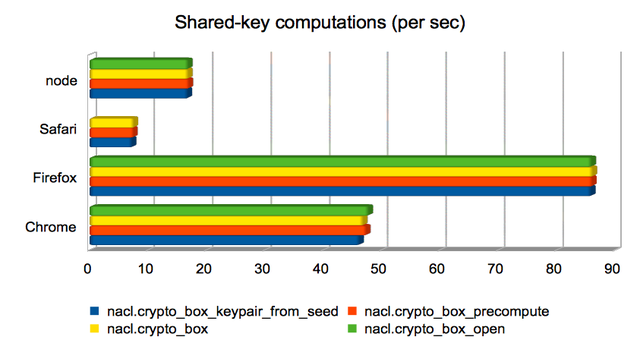
(Approximate speedups since January: Chrome = 2.5×; Firefox = 4.8×; Safari = 2×; node = 1×. Chart.)
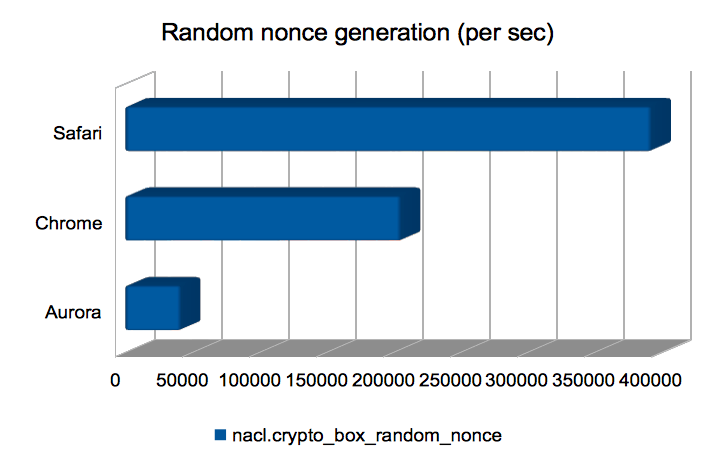
Computing random nonces
This is a thin wrapper over window.crypto.getRandomValues, or the
node.js equivalent, and so has not benefited from the emscripten
improvements. I’m including it just to give a feel for how fast
randomness-generation is.
Safari wins hands-down here. I wonder how good the generated
randomness is?
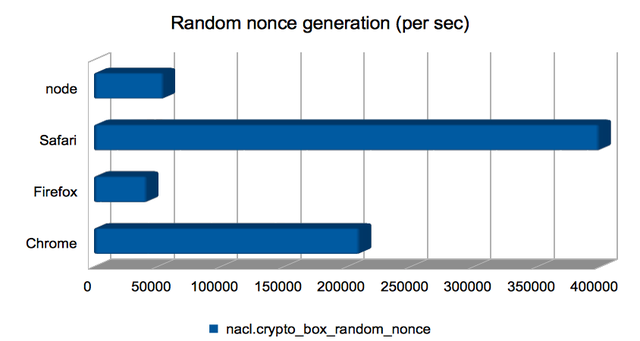
(Approximate speedups since January: Chrome = 0.96×; Firefox = 1×; Safari = 1×; node = 1×. Chart.)
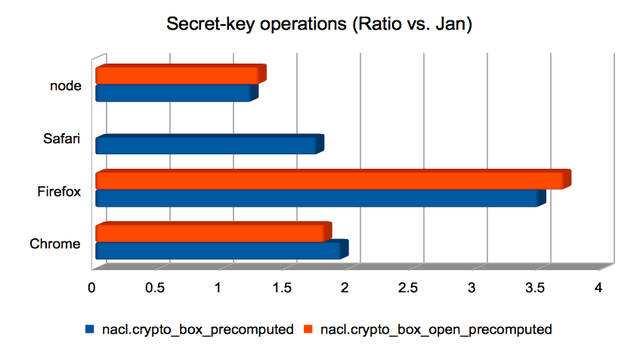
Authenticated encryption using a shared key
These are Salsa20/Poly1305 authenticated encryptions using a
precomputed shared key. Broadly speaking, boxing was quicker than
unboxing. Firefox again dominates.
This another of the areas where Safari yields incorrect results. I’m
not yet sure why.
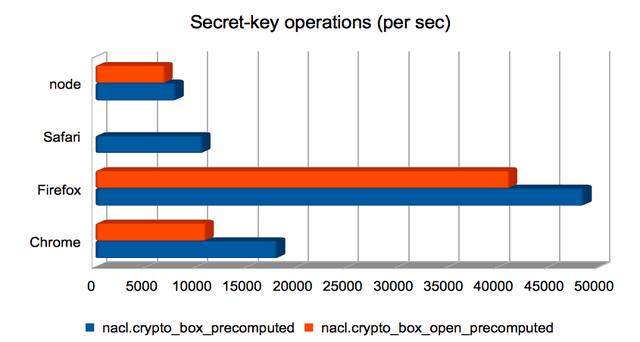
(Approximate speedups since January: Chrome = 1.5×; Firefox = 2.3×; Safari = 1.3×; node = 1.2×. Chart.)
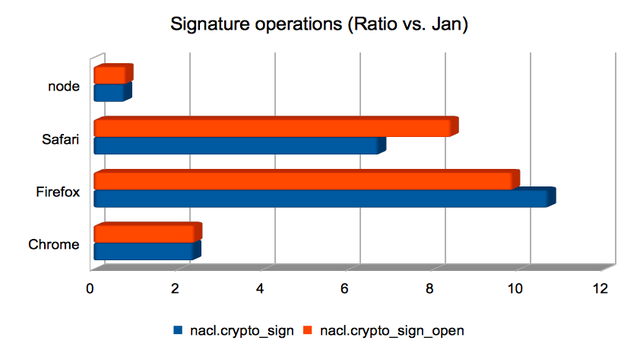
Producing and validating signatures
These operations compute an elliptic-curve operation, but use the
result to produce a digital signature instead of an
authenticated/encrypted box. Signature generation is much faster than
signature validation here. As for the other elliptic-curve-heavy
operations, Firefox is fastest, but Chrome is not far behind.
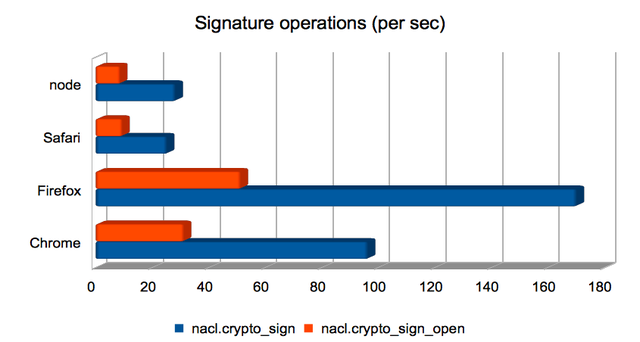
(Approximate speedups since January: Chrome = 1.8×; Firefox = 4.7×; Safari = 3.8×; node = 0.82×. Chart.)
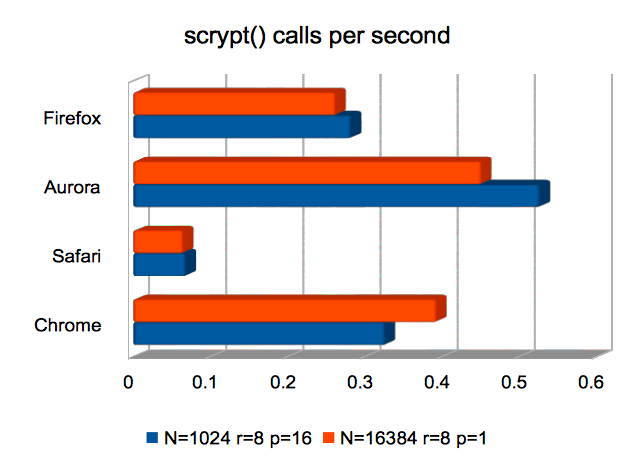
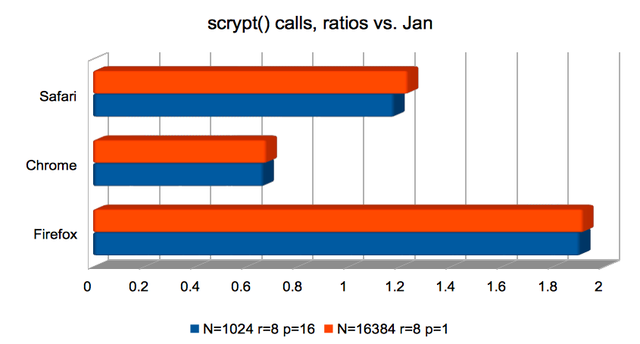
scrypt Key Derivation Function
Here, Safari not only underperforms significantly but computes
incorrect results. As above, I’m not sure why.
Firefox is about twice as fast as previously at producing
scrypt()-derived keys. Both Firefox and Chrome are usably fast.
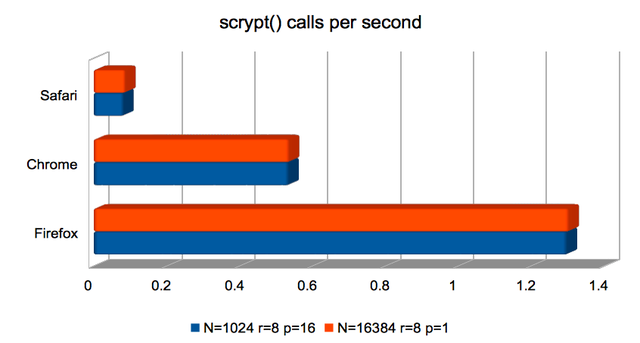
(Approximate speedups since January: Firefox improved by around 2×; the others were roughly unchanged. Chart.)
Conclusions
scrypt is still slow. Safari has problems with this code, or vice
versa. Precompute Diffie-Hellman shared keys where you can.
Emscripten + asm.js = very cool!



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}